Towards Robust End-to-End Diarization and Source Separation
Call: 30th Open Access Grant Competition; OPEN-30-22
Researcher: Mireia Diez Sánchez
Institution: Brno University of Technology
Field: Informatics
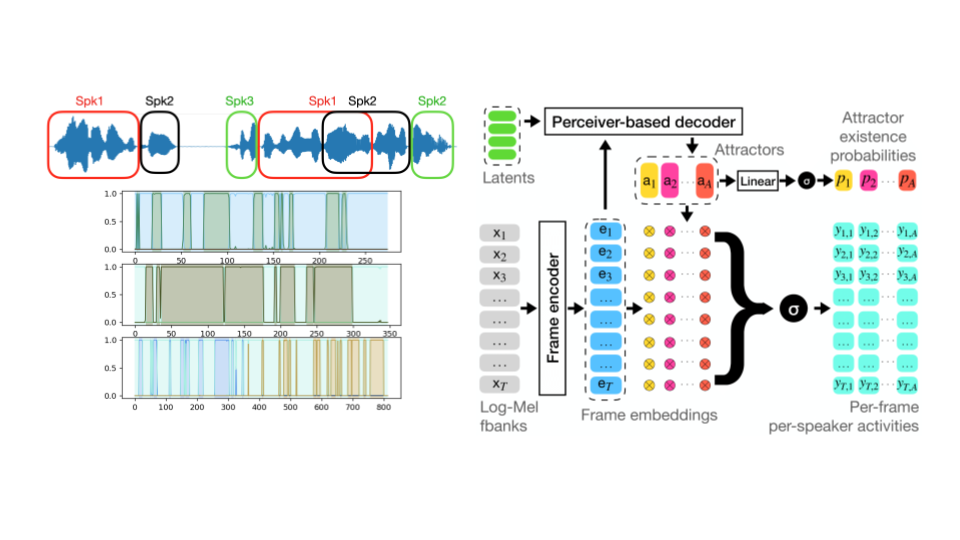 Speaker diarization (SD) is the task of automatically determining speaker turns in conversational audio, commonly known as the task that answers "who spoke when?". SD has several practical applications: indexing of audiovisual resources with speaker labels (for example, coloring subtitles depending on the speaker), allowing structured search and access to resources, meeting indexing, among others.
Speaker diarization (SD) is the task of automatically determining speaker turns in conversational audio, commonly known as the task that answers "who spoke when?". SD has several practical applications: indexing of audiovisual resources with speaker labels (for example, coloring subtitles depending on the speaker), allowing structured search and access to resources, meeting indexing, among others.
Besides, it is used as a preprocessing technique for other speech processing tasks, for example to allow speaker adaptation for automatic speech recognition (ASR) systems, also known as speech to text systems. Despite the big advances with large pretrained models such as the popular ChatGPT on conversational text processing, conversational audio processing is yet an extremely challenging task for machine learning approaches.
The recent development of neural network based end-to-end diarization (EEND) systems has boosted research in the field and shifted the paradigm on how to handle conversational speech. However, as most neural network based systems, EEND systems are data-hungry and difficult to train. In this project we plan to move the field forward by finding methods to optimize the training strategies; by combining the benefits of well-founded generative models with the powerful end-to-end approaches and by exploiting the synergies of the related speech processing tasks to enhance SD performance.
This research is closely related to several of the running projects at the Speech@FIT research group at the Faculty of Information Technology of the Brno University of Technology: NTT corporation, ROZKAZ, from the Ministry of Interior of the Czech Republic, and Eloquence, funded by Horizon Europe programme.
https://eloquenceai.eu/
3D Reconstruction and Feature Matching Benchmarks
Call: 30th Open Access Grant Competition; OPEN-30-13
Researcher: Assia Benbihi
Institution: Czech Technical University in Prague
Field: Applied Mathematics
3D reconstruction, or 3D mapping, is a computer vision task that produces digital 3D models of a scene. The 3D models can take various forms, the most common being 3D point clouds and meshes. They allow intelligent systems to perceive the physical which is a pre-requisite for the system to localize itself in an environment, understand what surrounds it, and adopt an appropriate course of action. 3D mapping is technology central to many applications including autonomous navigation, virtual and augmented reality applications, 3D content creation for movies and games, urban and environmental planning, and the documentation of cultural heritage.
Typically, the mapping process first scans the scene with various sensors, (cameras or laser scanners), then integrates the data within an optimization process to produce a 3D map that faithfully replicates the real world. A natural question arises: how to measure the faithfulness of the 3D map, in other words, how to measure the mapping quality?
Evaluation benchmarks answer this question by hosting accurate 3D models of scenes that act as ’pseudo-ground-truth’ digital twins. Any 3D mapping method can then be evaluated by how faithful it is to this digital twin. Such an evaluation is a reliable proxy but the generation of pseudo-ground-truth maps requires prohibitive computations, which makes 3D mapping benchmarks challenging to produce.
This project proposes a novel 3D mapping benchmark focused on large-scale urban scenes that include famous Prague landmarks such as Old Town Square or The Prague Castle. Access to supercomputers facilitates this computationally heavy project, in which complexity resides in the intensive optimization that generates pseudo-ground-truth maps, the evaluation of state-of-the-art methods that rely on graphic card advancements, and the large scale of the benchmark.
Part of the released data, mainly the geo-located images, is the outcome of a previous Karolina project, OPEN-28-60 “The Prague Visual Localisation Benchmark”, and the resulting benchmark will be a catalyst for research in 3D mapping. This project is part of and funded by the GACR EXPRO project “A Unified 3D Map Representation” (23-07973X), of which one outcome is the 3D mapping method `Tetra-NeRF’ showcased in the video and that was facilitated by the Karolina OPEN-24-6 project.
Discovery of Economic Opinions and Causal Relationships from Textual Data
Call: 30th Open Access Grant Competition; OPEN-30-3
Researcher: Jennifer Za Nzambi
Institution: Czech Technical University in Prague
Field: Informatics

Social media platforms are akin to an untapped gold vein harbouring a reservoir of public opinions, attitudes, and sentiments which, if realised, could revolutionise how public opinions are gathered and interpreted. This project introduces a novel method for extracting opinions about economic indicators and factor impacting society from social media texts by fine-tuning large language models, on datasets comprising of social media posts, comments and more. Through fine-tuning, language models can acquire the ability to understand and mimic the economic discourses within posts published on social media. This project’s value is threefold. First, it amalgamates carefully curated datasets through which the model can effectively learn domain-specificities and economic understanding on an advanced level. Second, it devises metrics based on perplexity comparisons of opposing statements which validate the model’s comprehension of economic texts, thereby measuring the model’s alignment with datasets it was fine-tuned on, and finally applies said models to datasets garnering results indicating that the model-based approach can rival, and in some cases outperform, survey-based predictions and professional forecasts in predicting trends of economic indicators. Beyond the scope of this study, the methods and findings presented could pave the way for further applications of language model fine-tuning as a complement, or potential alternative, to traditional survey-based methods.
This research is supported by the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme (grant agreement No 101002898).
Slama – Slavonic Large Foundational Language Model for AI
Call: 29th Open Access Grant Competition, OPEN-29-48
Researcher: Aleš Horák
Institution: Masaryk University
Field: Informatics

The Slama (Slavonic Large Foundational Language Model for AI) project aims to create a new foundational language model focusing on the main Slavonic languages with Latin script (Czech, Slovak, Polish, ...). The project's primary goal is to explore the performance differences between state-of-the-art pre-trained multilingual models (where English texts represent the majority of training data) and a model tailored specifically to the Slavic language group. The research will focus on developing generative models, the training data of which is more balanced in favour of the Slavonic language group rather than English. Therefore, the new model should provide better results when using AI tools processing mainly Slavonic languages. The resulting foundational model can then be easily applied to various AI tasks.
3D reconstruction for object manipulation
Call: 29th Open Access Grant Competition; OPEN-29-7
Researcher: Varun Burde
Institution: Czech Technical University in Prague
Field: Informatics
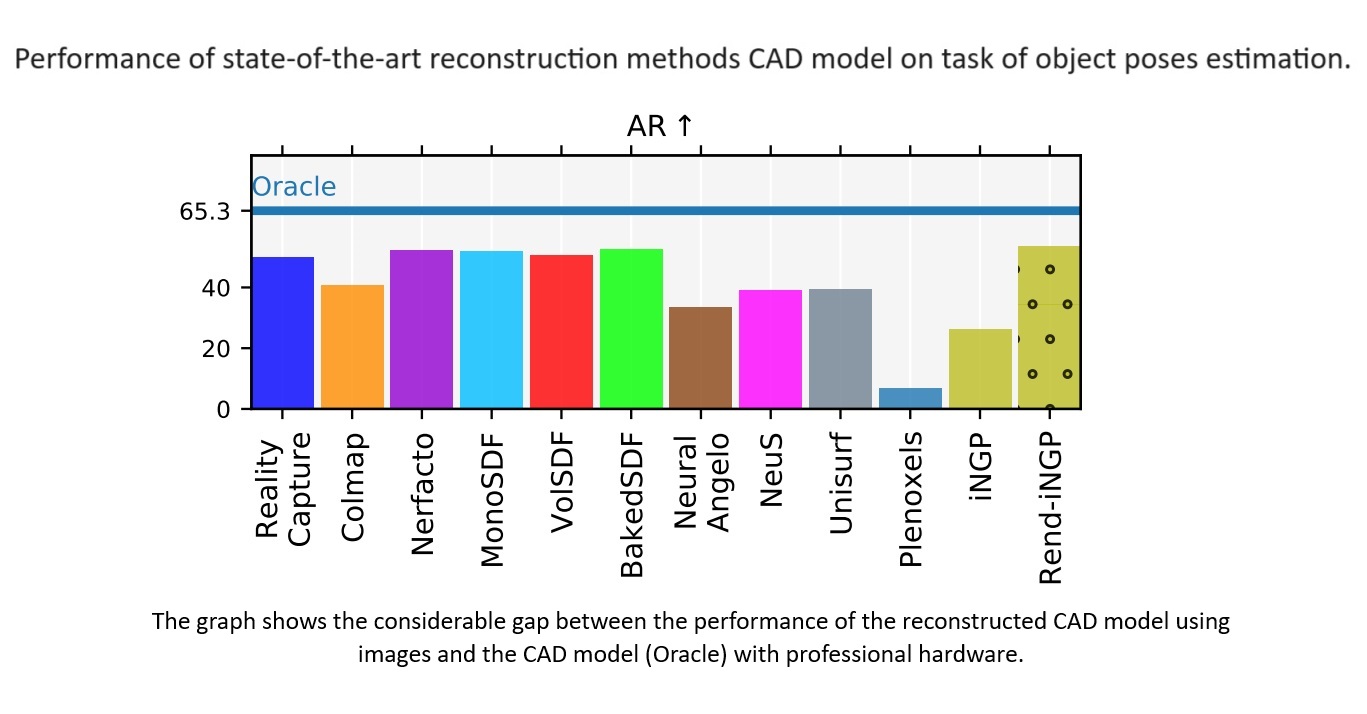
Manipulating objects is a core capability for many robots. A pre-requisite for manipulation is object pose estimation, where the goal is to estimate the position and orientation of the object relative to the robot, as this information informs the robot on how to interact with the object (how to approach, how to grasp, etc.). The current state-of-the-art object pose estimation algorithm relies on some representation to estimate the object pose. Obtaining highly accurate CAD models can be challenging and time-consuming and may require professional hardware such as a laser scanner. Our previous result showed that state-of-the-art methods can reconstruct simple objects well, but to accommodate a wider variety of objects, the current generation of algorithms needs to be significantly improved along multiple axes, such as runtime, robustness to environmental change, and accuracy of reconstruction/representation. Our research aims to accelerate 3D reconstruction techniques and leverage modern implicit object representation, enabling real-time deployment in robotics and accommodating more complex objects. IT4Innovations computing infrastructure provides a platform to work and train with large-scale datasets. The research is part of the Student grant competition of CTU No.: SGS23/172/OHK3/3T/13.
High Performance Language Technologies (HPLT)
Call: 28th Open Access Grant Competition; OPEN-28-66
Researcher: David Antoš
Institution: CESNET
Field: Informatics

Large language models (LLMs) are behind recent progress in Artificial Intelligence, especially in using natural language when communicating with computers. Pre-trained LLMs are in regular use by chatbots and search engines. Moreover, they make recommendations, classify speech and documents, and make many similar applications possible. LLM training is the domain of a few large companies, which usually do not pay much attention to reproducibility, bias minimisation, and energy efficiency, as well as equal treatment of all languages.
The goal of the HPLT project, coordinated by Charles University in Prague and supported by the Horizon Europe programme is to train open language models for over 50 languages. The project will ingest over 7 PB of archived web pages, parallel corpora, and other sources. Using IT4I computational resources, the largest collection of open, reproducible language and translation models will be built. The project will keep track of how the data has been extracted and how the models have been built, ensuring the highest standards of open science, reproducibility, and transparency.
Multi-Document Summarization from Scientific Literature
Call: 28th Open Access Grant Competition; OPEN-28-72
Researcher: Martin Dočekal
Institution: Brno University of Technology
Field: Informatics

Never in history have so many scientific papers been published as today. This fact makes it difficult even for experts to keep up to date, and it is relatively easy to overlook relevant information. Today, it is common for articles to be written summarising the state of the art in a particular field or for authors to set aside a special section in their article summarising related work. These texts make it easier to see the information in a broader context.
Producing such texts requires considerable human effort. However, thanks to advances in machine learning, it is possible to develop models to help with their production or to allow the user to create summaries on demand. Martin Dočekal's project aims to use the IT4Innovations computing infrastructure to train a neural network capable of generating summaries of a given group of scientific articles.
Deterministic Road Traffic Simulator – 2nd Phase
Call: 24th Open Access Grant Competition; OPEN-24-65
Researcher: Martin Šurkovský
Institution: VSB-TUO, IT4Innovations
Field: Informatics

The Deterministic Road Traffic Simulator is used to test algorithms for optimising road traffic flow in a city. To illustrate, a conventional navigation system navigates a car around a city by preferring the shortest route or the shortest travel time. This can lead to congestion in a city. Using a traffic simulator, we try to optimize the overall traffic flow so that congestion ideally does not occur at all. The deterministic nature of the simulator ensures that for the same input settings, the simulation result is always identical. This property is rarely ever satisfied in a supercomputer environment and is important in terms of comparing results and making them repeatable. The project is co-funded by Sygic and is also addressed in the framework of the European HORIZON 2020 project EVEREST, which deals with facilitating the optimal use of heterogeneous computing resources, i.e. both classical processors and dedicated accelerators.
THEaiTRE GPT2 Recycling
Call: special call within the 24th Open Access Grant Competition; OPEN-24-11
Researcher: Rudolf Rosa
Institution: Charles University
Field: Informatics

We used Ostrava supercomputers as part of our research and development at the Institute of Formal and Applied Linguistics at the Faculty of Mathematics and Physics of Charles University. Thanks to the powerful GPUs with a high memory capacity, we were able to train a Czech version of the large neural generative language model GPT-2. The generative language model is a tool that can, for example, propose a possible textual continuation for a given beginning; for example, for the text "I got up in the morning and went to [...]" it can predict for example "work" or "the bathroom". The GPT-2 model has so far only been available in English; we use its Czech version for example for the automatic generation of X-ray image descriptions or for generating theatre play scripts within the THEaiTRE project.
Estimating the poses of objects from images
Call: special call within the 24th Open Access Grant Competition; OPEN-24-10
Researcher: Valdimír Petrík
Institution: Czech Technical University in Prague
Field: Informatics

Our goal is to enable automatic learning of robotic manipulation skills, such as assembling a piece of furniture, by watching videos, for example, downloaded from YouTube. The camera type and its calibration are unknown for such videos, making it challenging to estimate the poses of the objects in the recorded scene. We address this challenge by FocalPose, a neural render-and-compare method designed for jointly estimating the relative pose between the camera and the object together with the camera focal length given a single RGB input image depicting a known object. FocalPose is trained on millions of synthetically generated images using several computing nodes on the Karolina supercomputer resulting in a robust estimator that works on noisy recordings of cluttered scenes. The work was published at CVPR 2022, a top-tier computer vision conference, which this year accepted 2064 from the 8161 submitted papers.
TRANSFER LEARNING FOR KEYPHRASE EXTRACTION
Call: 21st Open Access Grant Competition
Researcher: Martin Dočekal
Institution: Faculty of Information Technology, Brno University of Technology
Field: Informatics

It is becoming more and more apparent that in today's deluge of data it is difficult to find a relevant document containing the information we seek. We have reached a point where it is difficult for humans to find information without using an automated tool such as a search engine. However, even using a search engine, we get a large number of documents the relevance of which has to be decided by the user. Key phrases that bring the content of a document into a compact form can help with this problem. A common key phrase has only a few words. If it is only one word we call it a more familiar term, namely keyword.
In our project, we focus on extracting key phrases from large (over 83,000 words on average) Czech language documents such as books. The documents used are additionally burdened with errors as they were created by automatic digitization. The extracted key phrases from this kind of documents could be used by librarians in their work, among others.
To find key phrases, we use large-scale neural networks that are able to produce context-dependent representations of words. Based on these representations, the network then decides whether a given sequence of words can be considered a key phrase.
MASSIVELY MULTILINGUAL AND SELF-SUPERVISED NEURAL MACHINE TRANSLATION FOR LOW-RESOURCE LANGUAGES
Call: 20th Open Access Grant Competition
Researcher: Josef Jon
Institution: Brno University of Technology
Field: Informatics
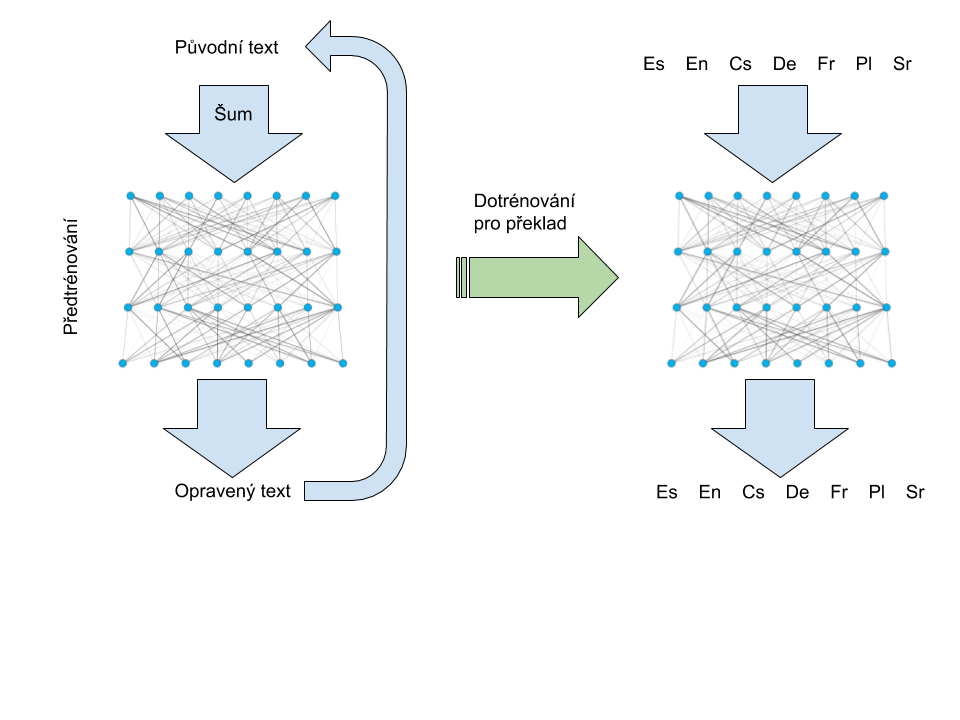
Machine translation of human language has made tremendous progress due to recent improvements in machine learning. Translations generated by neural machine translation (NMT), under specific conditions, are even comparable to human translation. One of these conditions is that for a given language pair, there are large numbers of parallel, human-translated texts available to train the model. This is true only for a very limited number of language pairs. Improving NMT quality in other languages is based on pre-trained models of neural networks to represent the language. These make it possible to take advantage of large volumes of texts found on the internet, but to which noise is artificially added, with some words being dropped or replaced. The challenge is to reconstruct the original text. By training on this task, the model actually learns to represent and understand language incidentally because these skills are needed to correct the text appropriately. Pre-trained models can be fine-tuned to end tasks using significantly less data than if they were trained from the beginning. It turns out that the more the method of adding noise in the pre-training phase is similar to the end task, the better the result. The aim of Josef Jon, an engineer who has acquired nearly 1.2 million core hours for his project, is to explore variations of noise functions that are similar to translation (e.g., replacing a word or phrase with its translation), and to use the resulting models for translation in language pairs with little training data.
DRVOSTEP – OPEN TRANSLATION
Call: 16th Open Access Grant Competition
Researcher: Martin Kolář
Institution: Brno University of Technology
Field: Informatics

DrVostep will investigate the limits of machine translation for hundreds of languages. The first output will be the analysis of translation quality with and without intermediate languages, such as CZ->DE versus CZ->EN->DE. A second result, benefiting the wider European community, will be an open machine translation website like google translate, but unlimited and free by performing client-side computations. More than 1.5 million core hours were awarded to Martin Kolář from Brno University of Technology to study the quality of translations for hundreds of languages. The current research is generally focused on the development of methods which learn to translate texts between two languages, with no research having been focused on translations among more than 6 languages so far. The objective of Martin Kolář’s project is to improve translation quality, to quantify the complexity of languages, and thus find the difference between the quality of direct translation as opposed to translation with an intermediate language. Using our supercomputer, the research team from Brno University of Technology aims to analyse hundreds of languages and develop an open online translator.
RESEARCH AND DEVELOPMENT OF LIBRARIES AND TOOLS IN THE INFRA LAB
Call: 15th Open Access Grant Competition
Researcher: Dr Petr Strakoš and Dr Lubomír Říha
Institution: IT4Innovations
Field: Informatics
Our colleagues from the IT4Innovations Infrastructure Research Lab were awarded almost 1.5 million core hours for developing the tools used by the users of our supercomputers in their research. The key topics of this project include energy efficiency in HPC, development of the numerical ESPRESO library, and visualization tools. The allocated computational resources will be used for analysis of the behaviour of new HPC applications and their dynamic tuning, with the objective to reduce the energy consumption when run on a supercomputer. In the case of the ESPRESO library, one of our research flagships, the research will be focused on solutions for, for example, improving single-node performance and in its deployment on systems with graphic accelerators. As far as the visualization tools are concerned, our colleagues aim to develop an open source tool for the visualization of scientific data which will be available to the users of our infrastructure. The visualization tool will be based on Blender, the popular 3D creation suite, in particular on its 2.80 version, which is to be released in the first quarter of this year.
ANALYSIS OF CAUSES AND PREDICTION OF PCRF EVENTS IN 4G AND 5G NETWORKS
Call: 15th Open Access Grant Competition
Researcher: Prof. Miroslav Vozňák
Institution: IT4Innovations the Faculty of Electrical Engineering and Computer Science at VSB-TUO
Field: Informatics

Our colleague Prof. Miroslav Vozňák and his team from the Faculty of Electrical Engineering and Computer Science at VSB-TUO were awarded almost half a million core hours for their project aimed at increasing the reliability and reducing the costs of maintaining new technologies to ensure mobile 4G and 5G network operation. This research is being carried out based on cooperation with the Centre of Excellence for network development operated by T-Mobile Czech Republic a.s. Together, they would like to find the key data sources, gather information about technical problems in one place, and identify performance indicators which can be used to increase reliability and prevent problems in the network. The data processing results obtained by the use of a supercomputer will serve as the basis for planned machine learning applications such as detection and classification of mobile network anomalies.
EXPERIMENTAL COMPARISON OF WORD EMBEDDING METHODS
Call: 12th Open Access Grant Competition
Researcher: Martin Fajčík
Institution: Brno University of Technology
Field: Informatics
.png)
Numeric representation of words used in natural language processing is referred to as word embedding. It consists in creating a vector for each word. Advanced word embedding methods have applications in various areas associated with, for example, speech recognition and translation. The objective of the project by Ing. Martin Fajčík from Brno University of Technology, which was awarded 850,000 core hours, is to experiment with state-of-the-art word embedding methods (count-based and prediction methods) by training them on large data sets. The team of scientists aim to identify the drawbacks of different methods, and find ways for their further improvement. The project activities also include developing deeper understanding of the relation between the vectors of words and their real meaning. Other interesting research topics will be processing of homonyms, synonyms, antonyms, and hyponyms. The models allow not only the relation between words they “learned” to be predicted but also the dimension of these relations to be represented. Moreover, they enable lexical arithmetic (e.g., the similarity between words).
ESPRESO FEM – HEAT TRANSFER MODULE
Call: 10th Open Access Grant Competition
Researcher: Dr Tomáš Brzobohatý
Institution: IT4Innovations
Field: Informatics

The project by Dr. Tomáš Brzobohatý “ESPRESO FEM – Heat Transfer Module“ has been awarded 2,425,000 core hours. The research team will focus on developing and testing the finite element method-based complex and massively parallel library for performing simulations of heat transfer problems, and their optimization. This library includes the massively parallel iterative ESPRESO solver continually developed at IT4Innovations.
BEM4I – DEVELOPMENT OF THE PARALLEL BOUNDARY ELEMENT LIBRARY II
Call: 9th Open Access Grant Competition
Researcher: Michal Merta
Institution: IT4Innovations
Field: Informatics

The researchers from IT4Innovations will continue to develop the library of parallel boundary element method (BEM)-based solvers. Within the previous project implementation, this (BEM4I) library was accelerated using the Intel Xeon Phi processors (Knights Corner, KNC), which complemented the already existing and operating parallelization using Open MPI. In this stage, it will be focused on further code optimization and its testing on the new generation of Intel Xeon Phi processors (Knights Landing, KNL). The objective of this project is to develop an efficient library for fast solution of boundary integral equations. The researchers will be involved in vectorization of system matrices and distributed memory parallelization. BEM4I could be used for solving real engineering problems in the field of sound propagation or shape optimization.